在780M核显笔记本上通过LM Studio本地化部署DeepSeek大模型
本来想用Ollama部署LLM,但我下载启动Ollama后发现官方不支持我的Radeon 780M核显(gfx1103):
1
2
3
4
5
6
7
8
9
10
11
12
| C:\Users\lincannm>ollama serve
2025/02/01 18:01:29 routes.go:1187: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://127.0.0.1:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:C:\\Users\\lincannm\\.ollama\\models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:0 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://*] OLLAMA_SCHED_SPREAD:false ROCR_VISIBLE_DEVICES:]"
time=2025-02-01T18:01:29.821+08:00 level=INFO source=images.go:432 msg="total blobs: 0"
time=2025-02-01T18:01:29.822+08:00 level=INFO source=images.go:439 msg="total unused blobs removed: 0"
time=2025-02-01T18:01:29.823+08:00 level=INFO source=routes.go:1238 msg="Listening on 127.0.0.1:11434 (version 0.5.7)"
time=2025-02-01T18:01:29.825+08:00 level=INFO source=routes.go:1267 msg="Dynamic LLM libraries" runners="[cuda_v12_avx rocm_avx cpu cpu_avx cpu_avx2 cuda_v11_avx]"
time=2025-02-01T18:01:29.825+08:00 level=INFO source=gpu.go:226 msg="looking for compatible GPUs"
time=2025-02-01T18:01:29.825+08:00 level=INFO source=gpu_windows.go:167 msg=packages count=1
time=2025-02-01T18:01:29.825+08:00 level=INFO source=gpu_windows.go:214 msg="" package=0 cores=8 efficiency=0 threads=16
time=2025-02-01T18:01:30.397+08:00 level=WARN source=amd_windows.go:140 msg="amdgpu is not supported (supported types:[gfx1030 gfx1100 gfx1101 gfx1102 gfx906])" gpu_type=gfx1103 gpu=0 library=C:\Users\lincannm\AppData\Local\Programs\Ollama\lib\ollama
time=2025-02-01T18:01:30.400+08:00 level=INFO source=gpu.go:392 msg="no compatible GPUs were discovered"
time=2025-02-01T18:01:30.400+08:00 level=INFO source=types.go:131 msg="inference compute" id=0 library=cpu variant=avx2 compute="" driver=0.0 name="" total="27.8 GiB" available="20.3 GiB"
|
听说还有个叫做LM Studio的东西,对我这样的780M核显支持不错,可以直接用。而且Ollama是命令行使用,而LM Studio则是GUI操作,更加人性化。
下载与安装
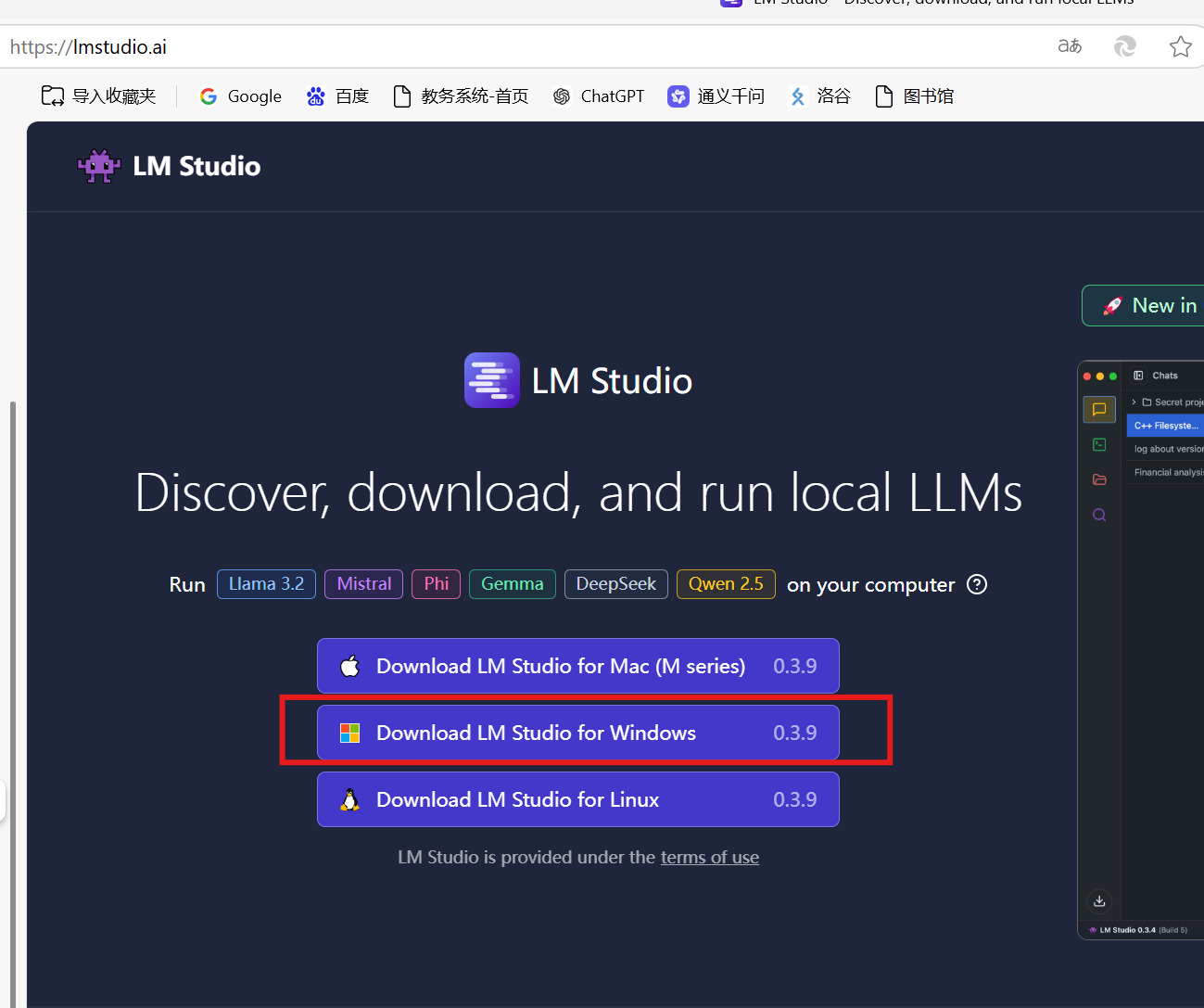
LM Studio官网:https://lmstudio.ai/
下载它:
安装就不必多说了吧。
使用
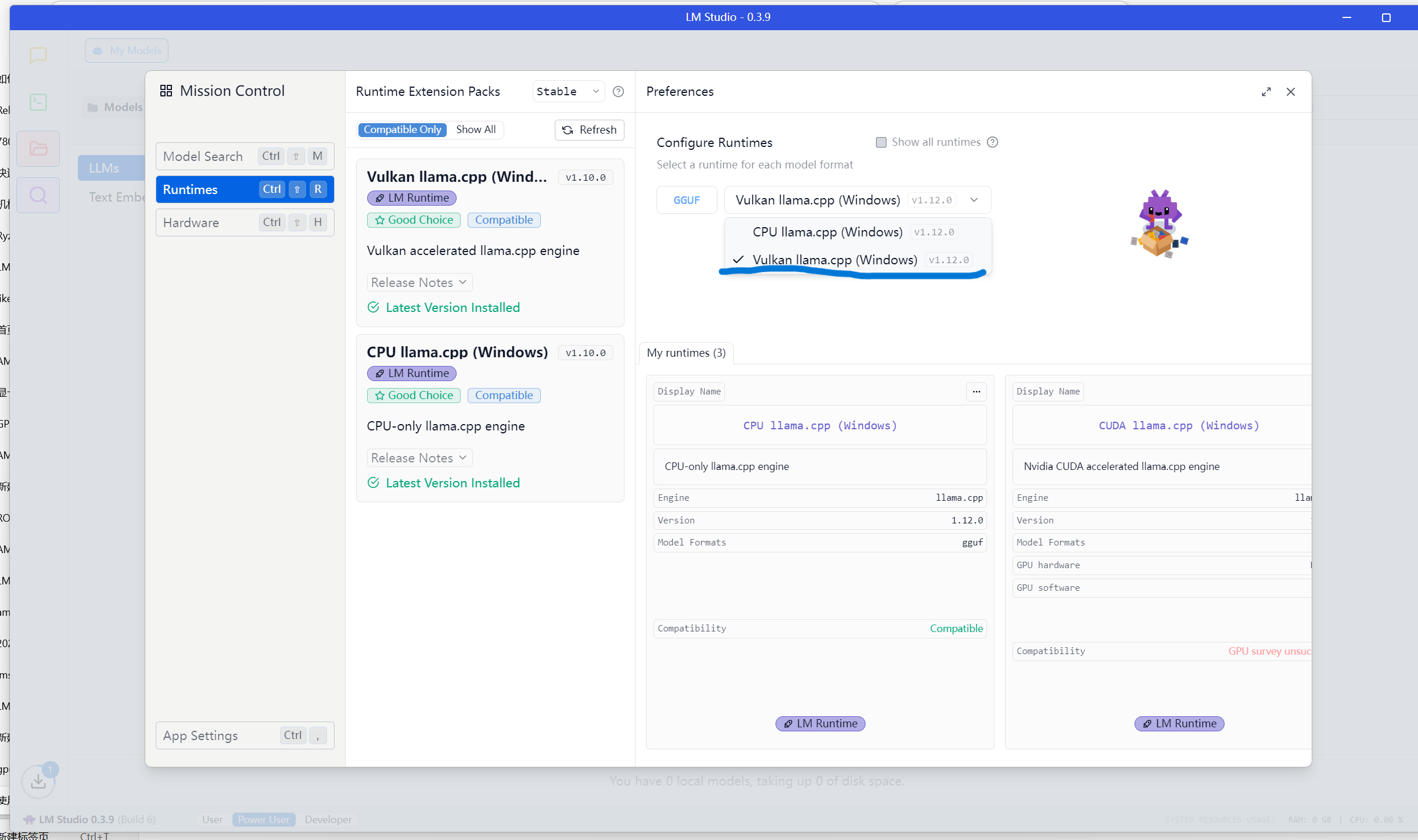
点开侧边栏第四个图标,弹出此“发现”窗口。首先到这里看看,由于我的GPU是AMD Radeon 780M,在这里看看确保选中了Vulkan选项,这样运行LLM的时候才会调用到显卡。
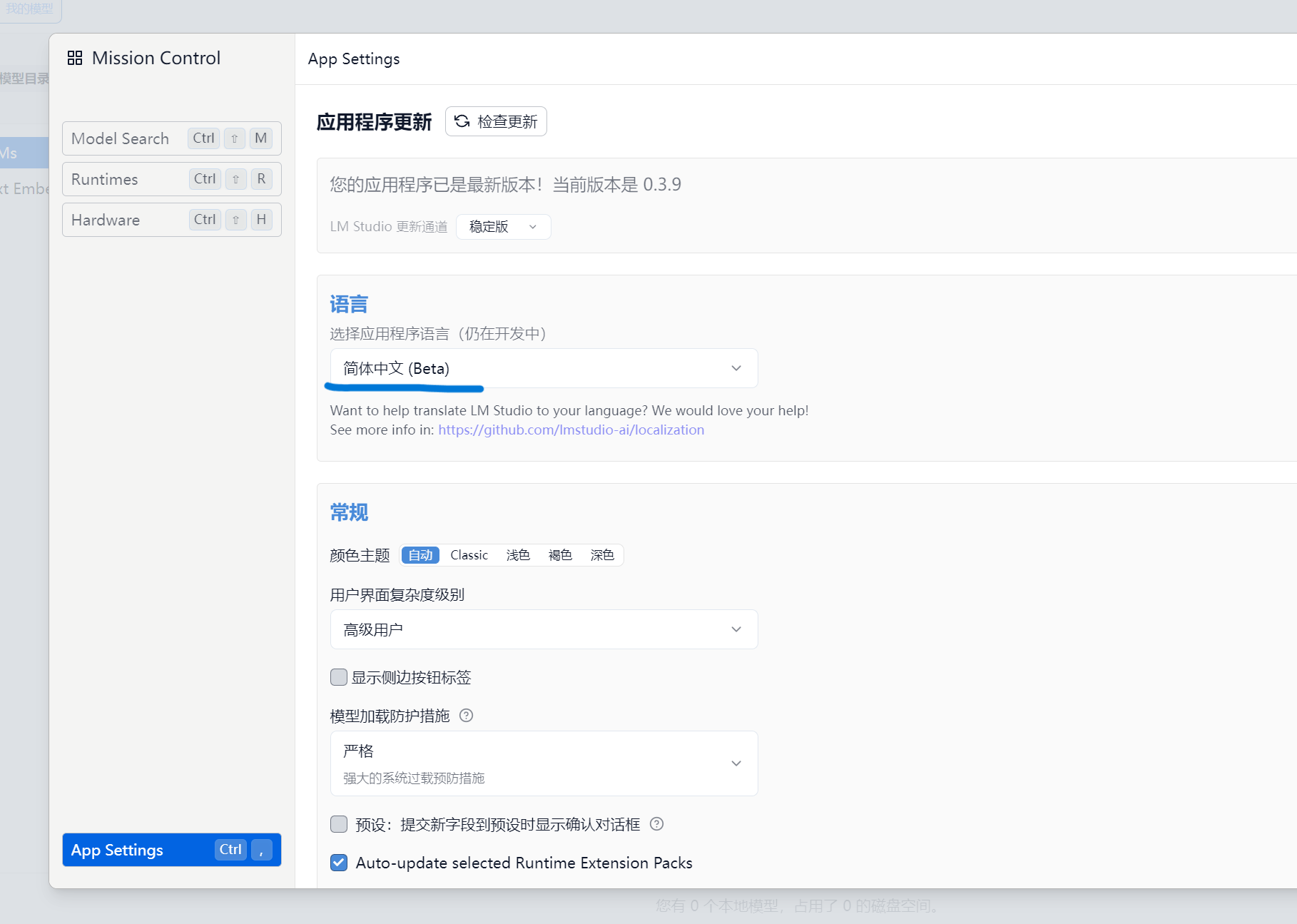
App Settings可以设置界面为中文。
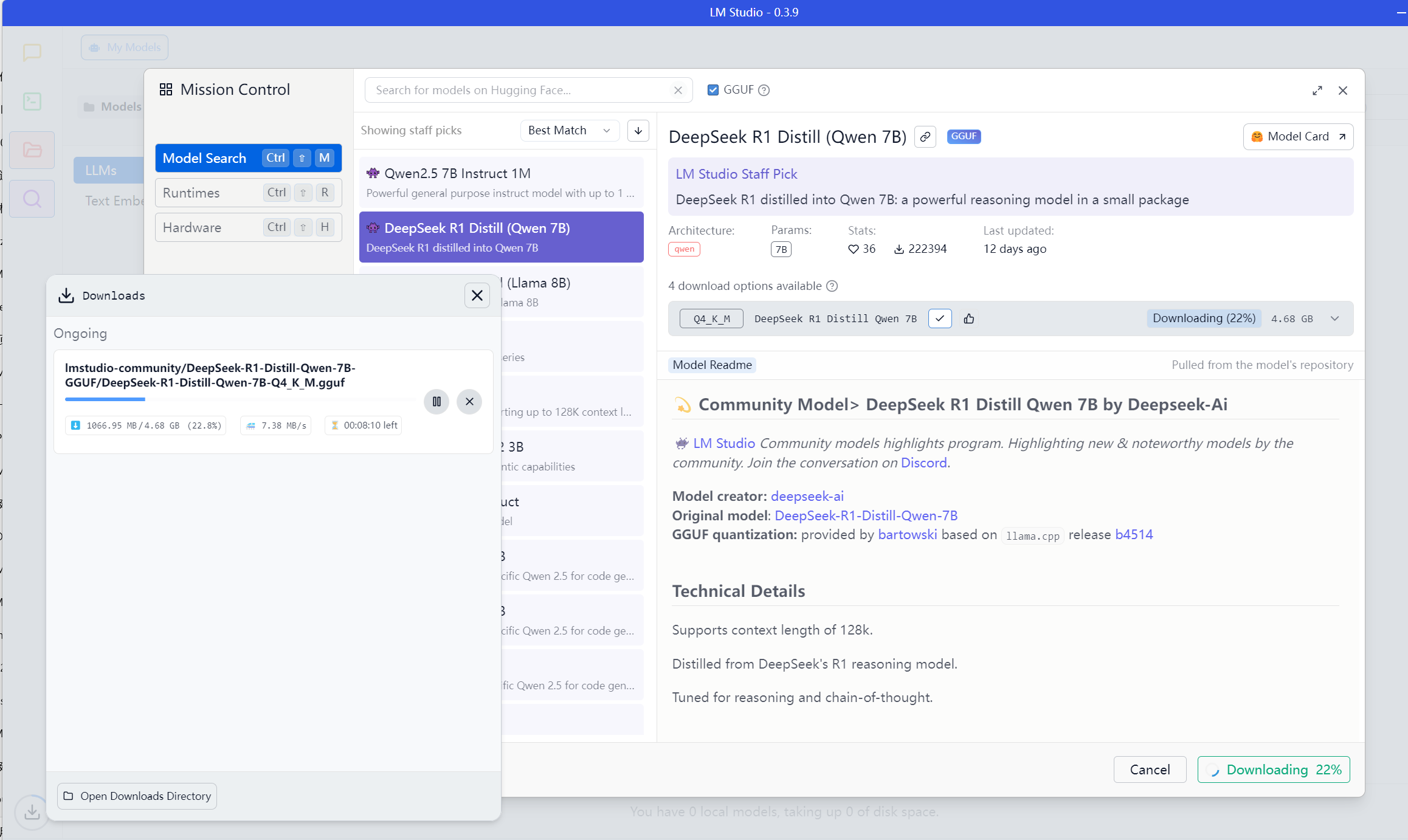
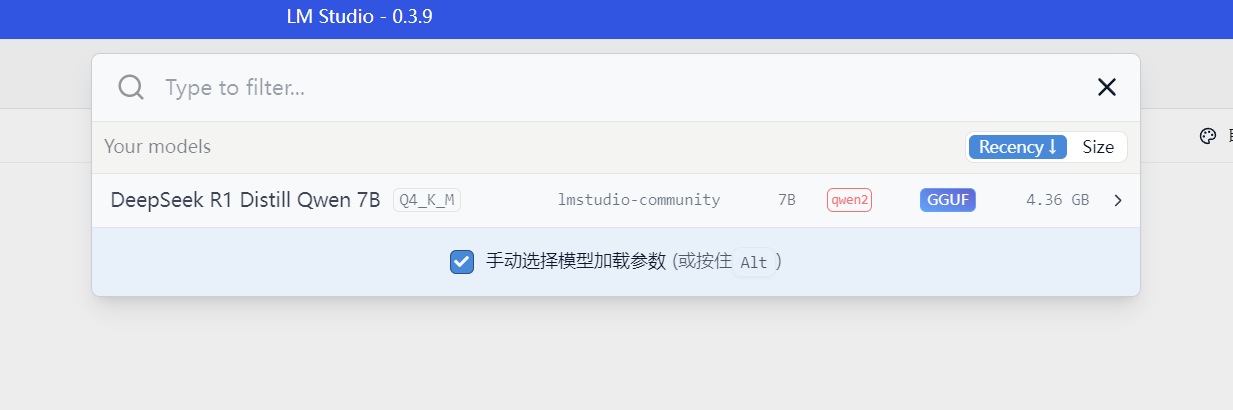
到“Model Search”下载DeekSeek模型。由于我的显存只有可怜的4G,我就下载大小为4G左右的7B版本就好。
下载完成!回到聊天界面,到顶栏选择模型。
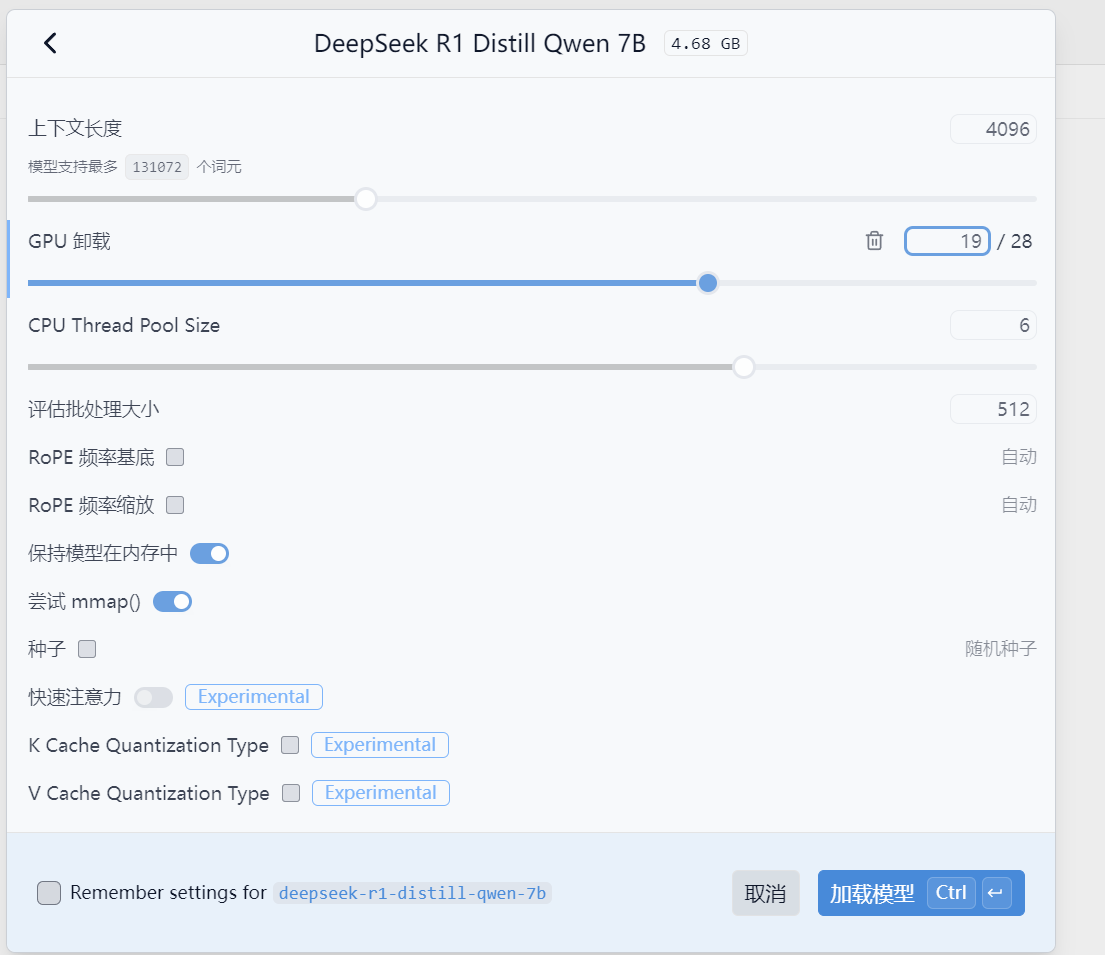
根据电脑配置配置这些配置~(GPU Offload被译为GPU卸载有点别扭,网上查了一下,其实就是根据当前GPU的显存性能来调节线条,值越高,就意味着运行模型的性能占比交给GPU的更高)
点一下加载模型就加载好了。部署到此结束,整个过程都非常简单。
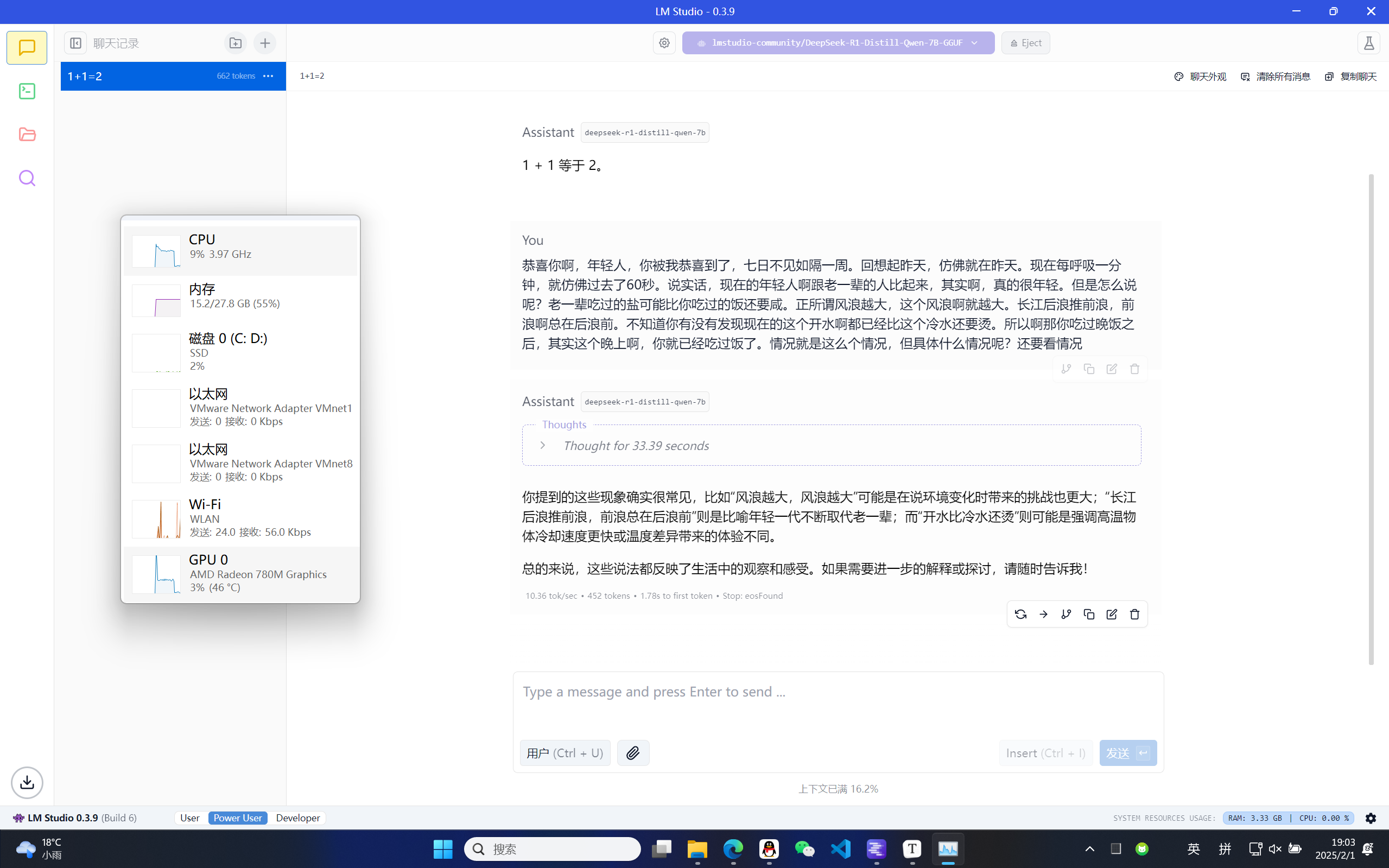
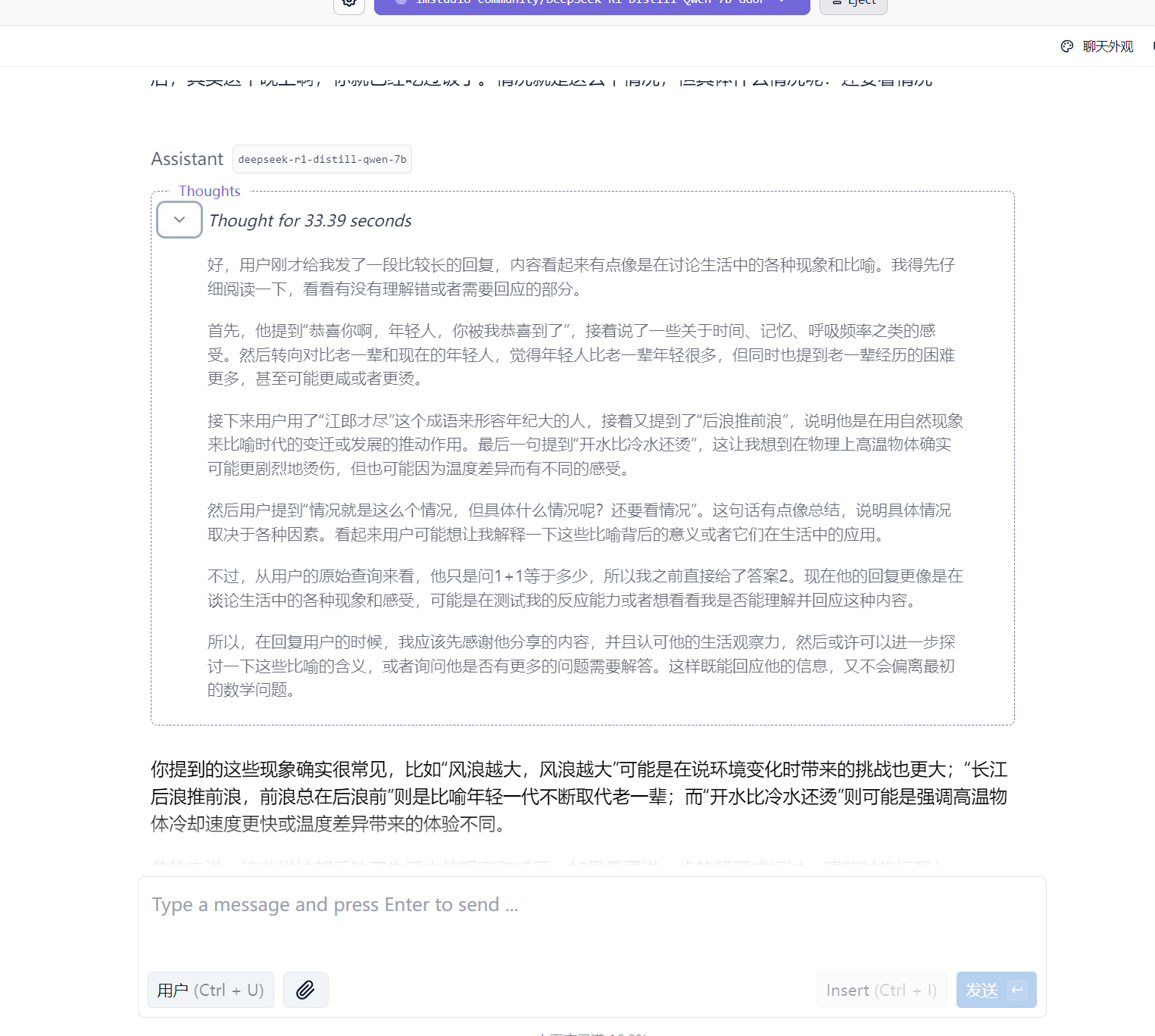
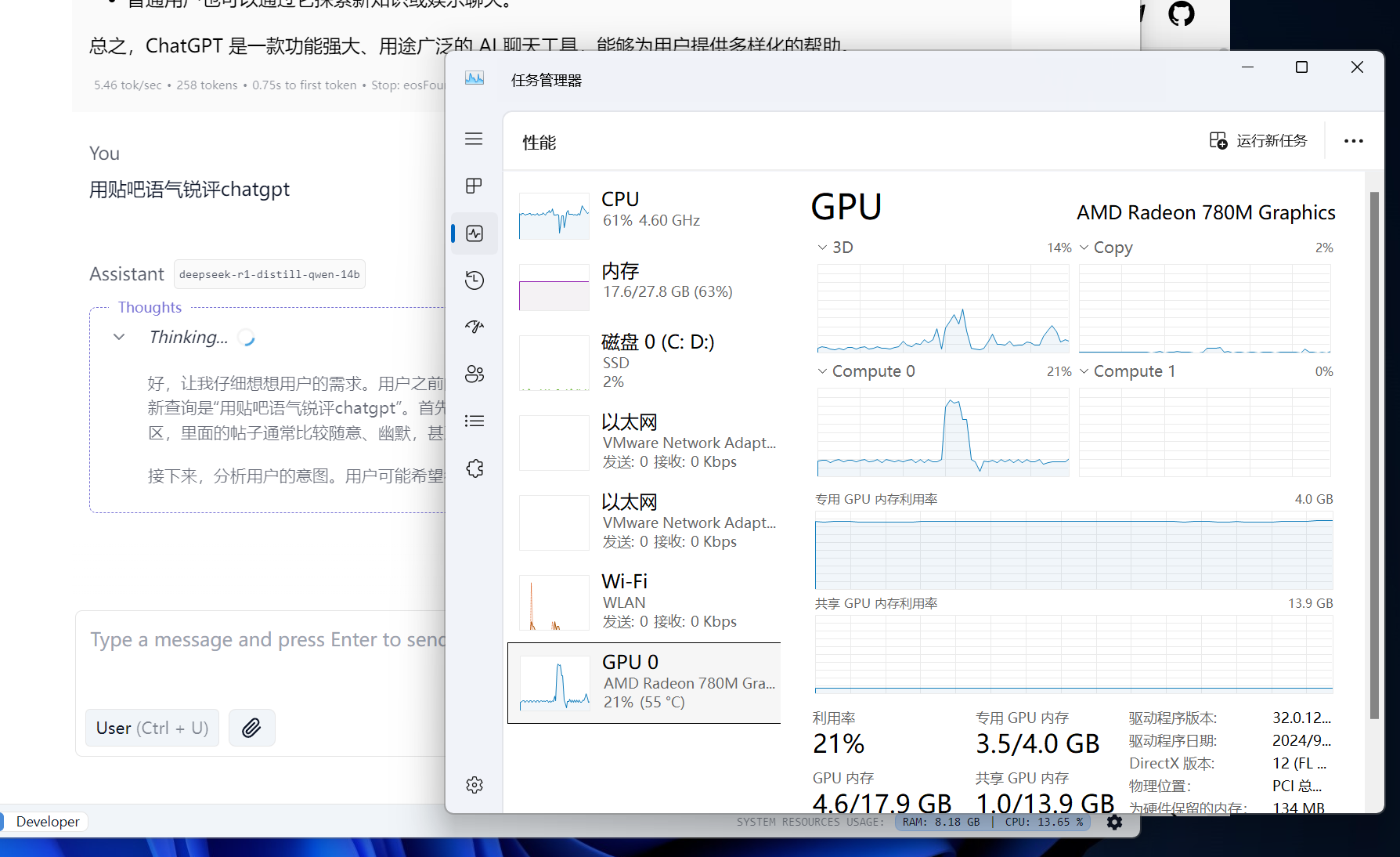
开始聊天,思考过程中笔记本风扇直接起飞。
回复太人机了,完整版DeepSeek会跟我解析这段话的幽默性。这样也很正常,完整版671B,我才7B的模型根本比不了。
网络优化
我是翻墙出去下载的模型,如果没有翻墙条件的话可以打开LM Studio安装目录,用vscode把目录下所有文件做全局替换——把所有huggingface.co替换为hf-mirror.com即可。
问题
不知道为什么我的核显占用很小,几乎闲着,而且一把GPU Offload调大就报Unknown error。。。全网找不到解决办法。
后来我下载了14B的模型,终于懂得解析幽默性了,这下就聪明多了。但是我让它用贴吧语气锐评ChatGPT,依旧不聪明,甚至都不知道是在骂ChatGPT还是在骂我。。。
问题解决
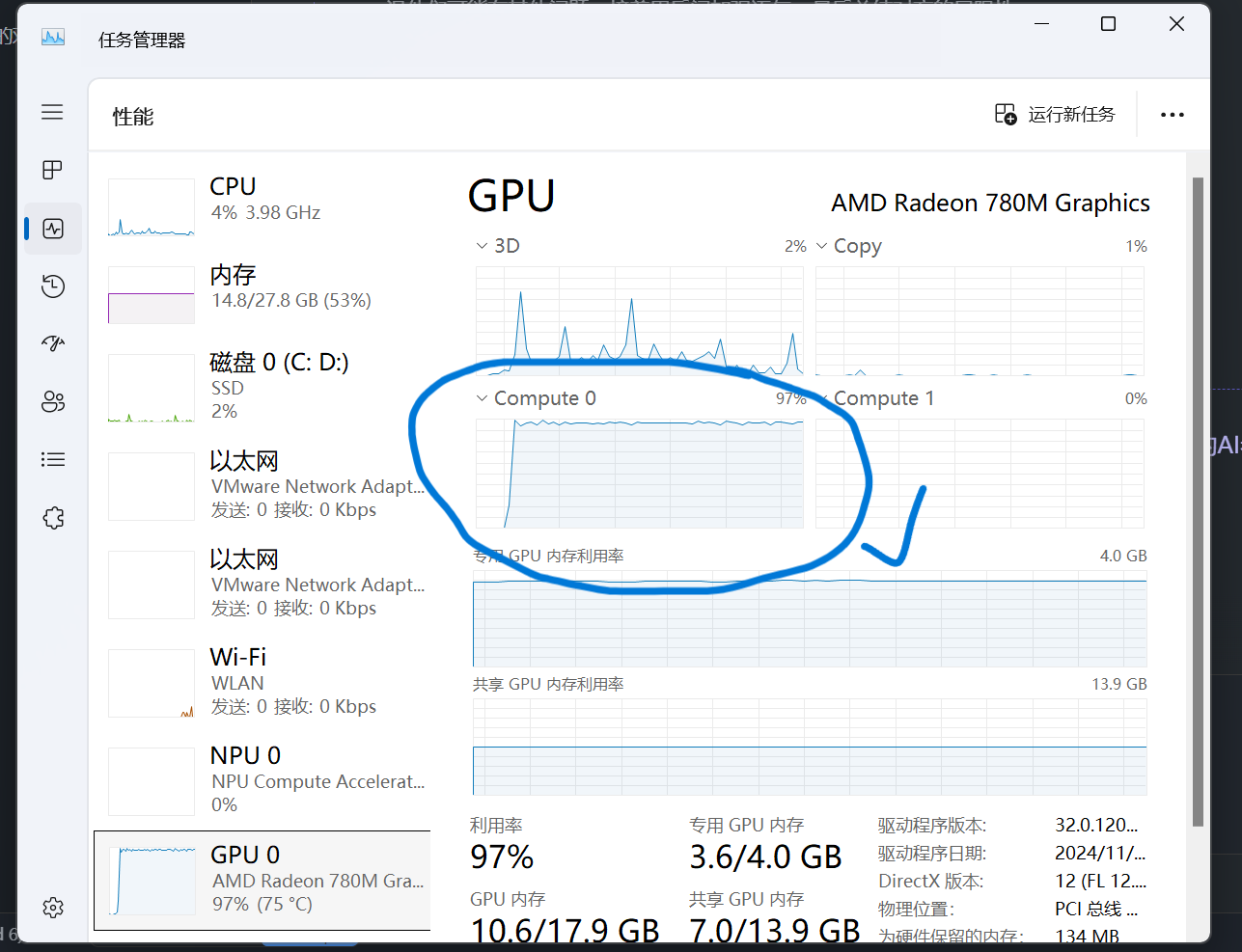
核显占用小的问题解决了!搞了两天原来更新一下amd显卡驱动就好了。。。更新了之后,GPU Offload可以全部拉满,可以全部交给显卡计算了。
Ollama-for-amd
在那个问题解决之前,试了一下Ollama-for-amd项目(https://github.com/likelovewant/ollama-for-amd/),该项目针对amd显卡进行支持性扩展,通过这个项目我的780M也能跑ollama了。安装的话直接下载Release里面的exe就行了。
然而聊天会有bug,不仅没有深度思考过程,后面我每说一句它还只会直接接我的话。不过既然问题解决了,干脆接着用LMStudio算了吧。